GPT Detectors
GPT Detectors</>
The data this week comes from Simon Couch’s detectors R package, containing predictions from various GPT detectors. The data is based on the pre-print: GPT Detectors Are Biased Against Non-Native English Writers. Weixin Liang, Mert Yuksekgonul, Yining Mao, Eric Wu, James Zou.
language model-based chatbot ChatGPT is reportedly the fastest-growing consumer application in history, after attracting 100 million active users just two months after it was launched. It’s easy to see why. The ability for such models to create large amounts of content within such a short period of time has opened the door wide open in terms of boosting productivity and creativity. From building cover letters for job applications to setting up company OKRs and everything in-between, people are using it in all kinds of ways. AI is even being used to detect AI-generated content, but how accurate has it been so far?
Liang et al. set out to test the accuracy of several GPT detectors:
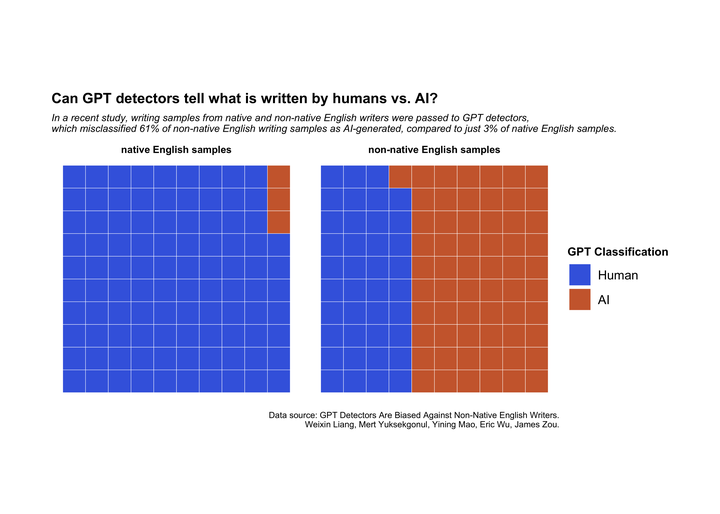
The study authors carried out a series of experiments passing a number of essays to different GPT detection models. Juxtaposing detector predictions for papers written by native and non-native English writers, the authors argue that GPT detectors disproportionately classify real writing from non-native English writers as AI-generated.
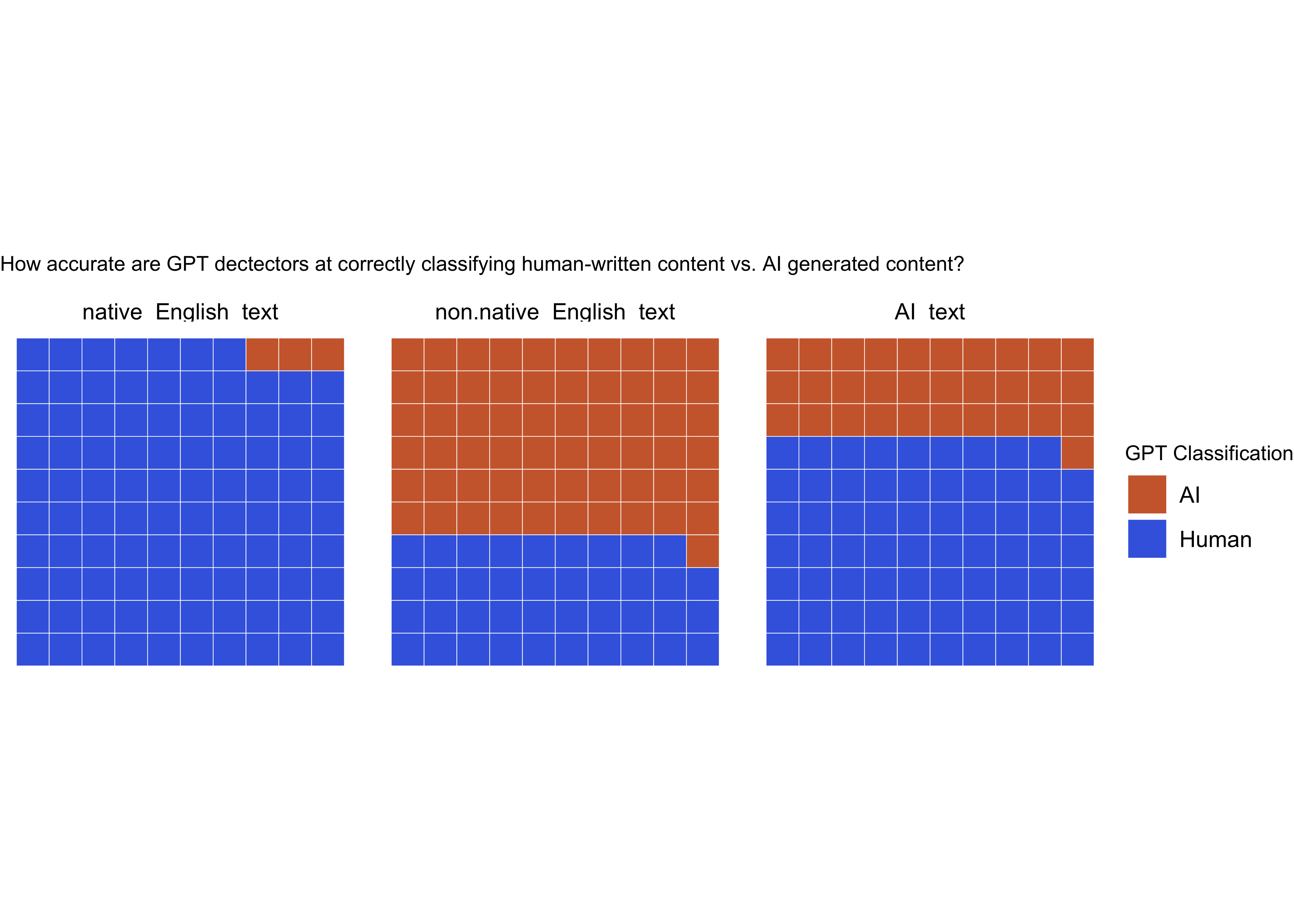
From the data, I was able to determine that GPT detectors correctly identified native English writers in 97% of cases, with only 3% being misclassified as AI-generated. However, the same was not true for non-native English writing samples, which were only correctly identified in 39% of cases.
Interestingly, AI incorrectly identified AI-generated content as being created by a human in 69% of cases.
| predicted_class | native_English_text | non.native_English_text | AI_text |
|---|---|---|---|
| Human | 97 | 39 | 69 |
| AI | 3 | 61 | 31 |
I used a waffle chart to display the data because I think it’s a great way to visualise the small number of categories and is easy to interpret and understand. This was my first waffle chart, so there was a lot of trial and error! I struggled to work out the correct variables to map at first (I kept getting a reps() error), but once that was sorted it was relatively smooth sailing.
I worked out how to reformat my data by changing from a “wide” format with each variable in its own column to a “long” format, so I could facet the data correctly. Then I changed the titles
I also discovered theme(plot.margin = unit()), which I used to change the margins of my plot.
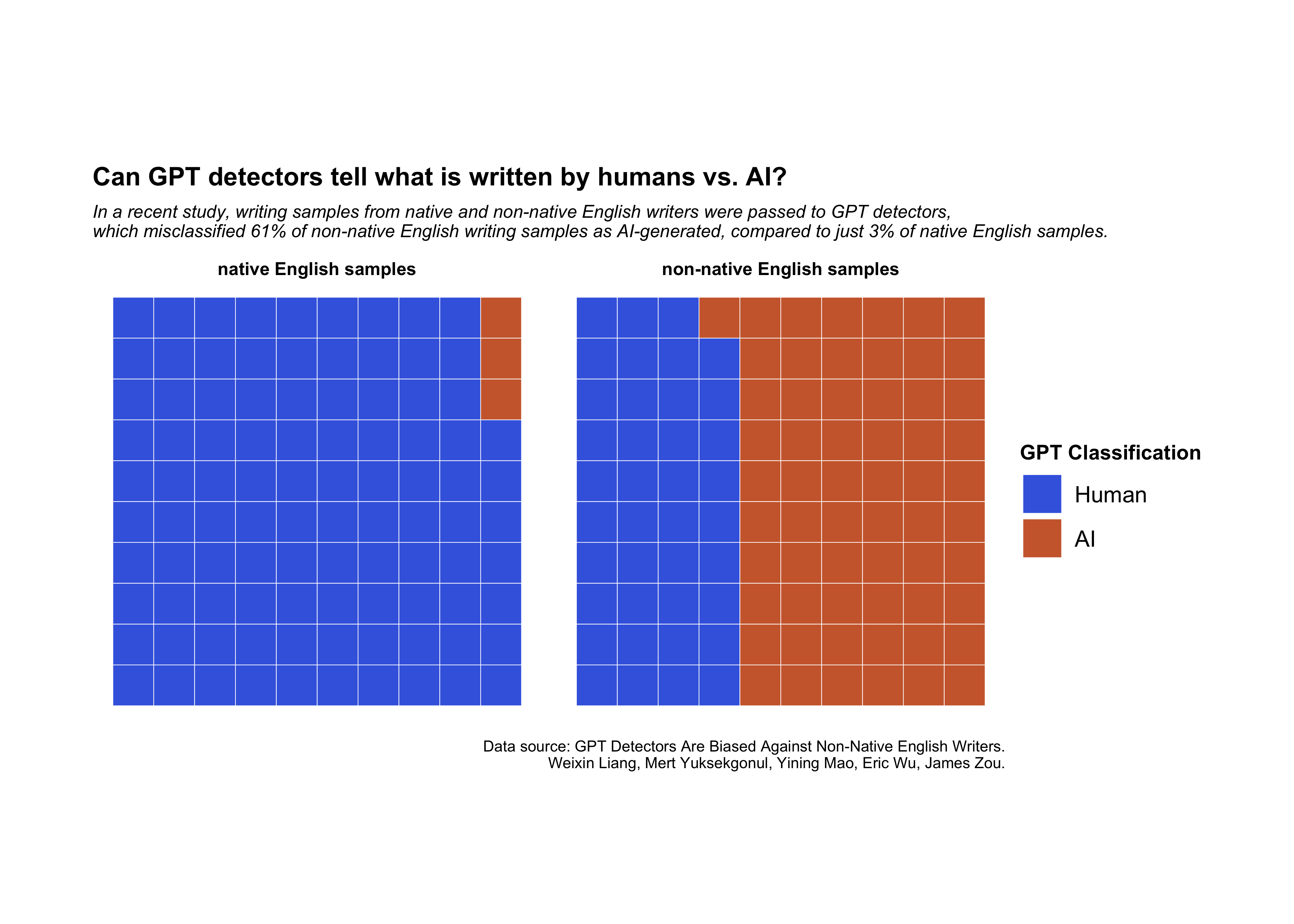
I originally opted to use the iron() function to knit all three waffle charts together, but it didn’t give me as much freedom to tweak and alter the plot as facet_wrap(), so I switched it up. I also chose not to include the AI-generated content waffle chart, because it seemed to make the chart more complicated (with the headline/subline especially) than I wanted it to be.
knitr::opts_chunk$set(warning = FALSE, message = FALSE)
#human and AI
ggplot(gpt2datalong, aes(values = value, fill = predicted_class)) +
geom_waffle(rows = 5, na.rm = FALSE, show.legend = TRUE, flip = TRUE, colour = "white") +
facet_wrap(~measure) +
theme(panel.spacing.x = unit(0, "npc")) +
theme(strip.text.x = element_text(hjust = 0.5)) +
coord_equal() +
theme_void() +
scale_fill_manual(values = c("sienna3", "royalblue")) +
labs(
title = "How accurate are GPT dectectors at correctly classifying human-written content vs. AI generated content?",
subtitle = "",
fill = "GPT Classification") +
theme(
plot.title = element_text(size = 8, hjust = 0),
plot.subtitle = element_text(size = 5, face = "italic"),
legend.title = element_text(size = 8))